Four billion messages an hour - benchmarking deepstream throughput
When it comes to benchmarking realtime systems, there are three core metrics to watch out for:
Latency: the speed at which updates traverse the system
Concurrency: the number of simultaneous clients
Throughput: How many updates can be sent to clients in a given time
We’ve concentrated on latency and to some extent concurrency in the last set of benchmarks, but now it’s time to look into throughput.
A real world test
It’s important to stress that our benchmarking approach aims to identify the best possible performance for real-world messages and cost-efficient infrastructure setups. It is perfectly possible to increase the achieved test results by up to 400% by reducing messages to single character events and reserving dedicated, network optimized bare metal instances, but the use of these metrics would be of very debatable value.
Test Setup
We ran two suites of tests, one for a single deepstream node, one for a cluster of six nodes. In both scenarios, a single provider pumped simulated foreign exchange rate updates into deepstream which were distributed across a number of connected test-clients.
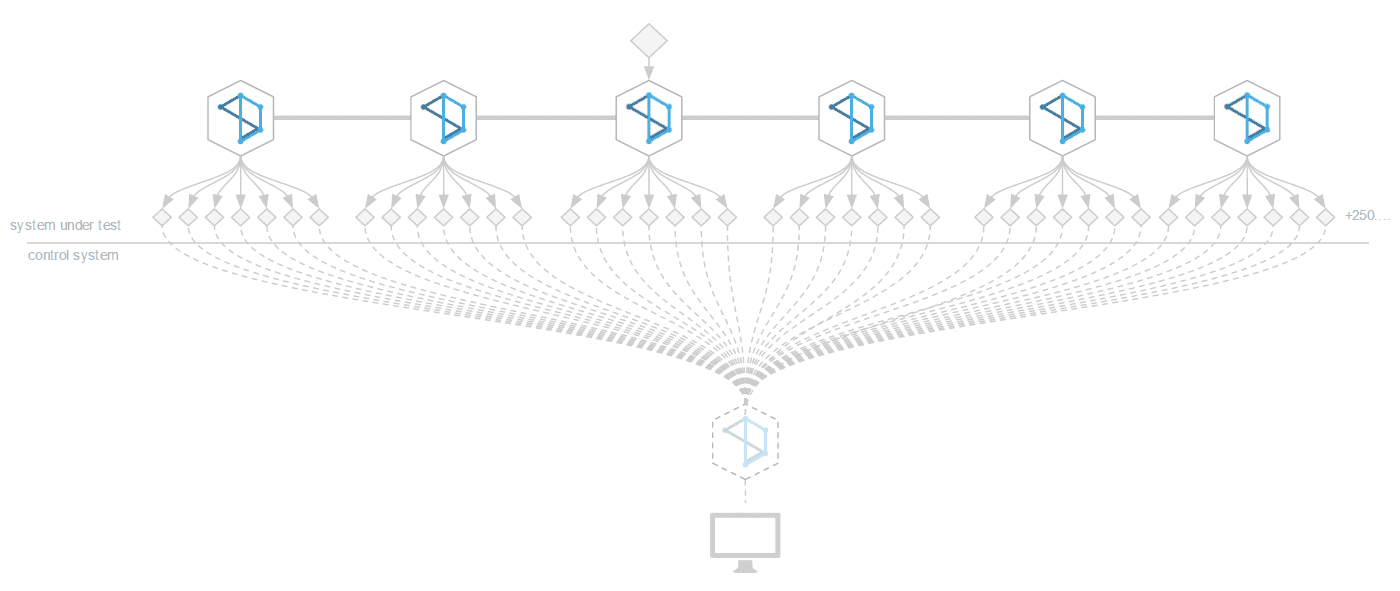
We’ve open-sourced all aspects of our test-framework. If you’d like to run the tests yourself or benchmark your custom setup, please find them here
Test Clients
We’ve developed a remote-controllable “probe” that can be used as both client and data-provider. Each probe is an independent process within a docker container that connects to a control deepstream-server upon startup and waits for further instructions.
Whenever a probe comes online, its presence is reported to a browser based dashboard using deepstream’s listen feature. From this dashboard it is possible to configure each probe, set its role as a client or a provider, its update frequency and subscriptions and connect it to any given deepstream node.
High level metrics from the probe, e.g. messages received or send in the last second are streamed to the dashboard and aggregated there. Lower level system metrics like CPU usage or memory consumption are aggregated on the individual machines using the top linux process manager and collected at the end of the tests.
Server Machines
Our tests were run on Amazon Web Services infrastructure. deepstream nodes are single-threaded processes with non-blocking I/O that scale via clustering. This makes it is possible to utilize multi-core CPUs by running multiple deepstream nodes on the same machine - but with the downside that nodes are subject to the limitations of that machine (ephemeral port limits, thread and memory allocation, single point of failure if the machine goes down etc.).
We therefore went with the recommended approach of spreading deepstream servers across multiple smaller machines, leading to higher fault tolerance, better resource utilisation and horizontal scalability. After extensive evaluation we found that EC2 t2.medium instances provide the best performance-to-cost ratio and used this instance type to host the servers in our test.
Messages
To allow for realistic message sizes, we’ve used simulated foreign exchange price update events as messages. Each event had a name such as fx/gbpusd (foreign exchange rate for pound against dollar) and transmitted a single floating point number with a five digit precision, e.g. 1.34325. This results in an average message size of ~23bytes. The number is changed for every update and events are distributed over hundreds of different topics.
Results - Single Node
Time to start exploring the limits of a single node, starting with CPU consumption. We’ve clocked the maximum throughput of an individual deepstream at 400,000 events per second on a c4.2xlarge high CPU machine. That’s good to know, but collides with our best value for money performance testing policy. On c4.2xlarge, sending a billion messages cost 36 cents.
Moving towards a way more affordable t2.medium instance, we found a sweet spot for CPU utilisation between 160k and 200k messages per second.
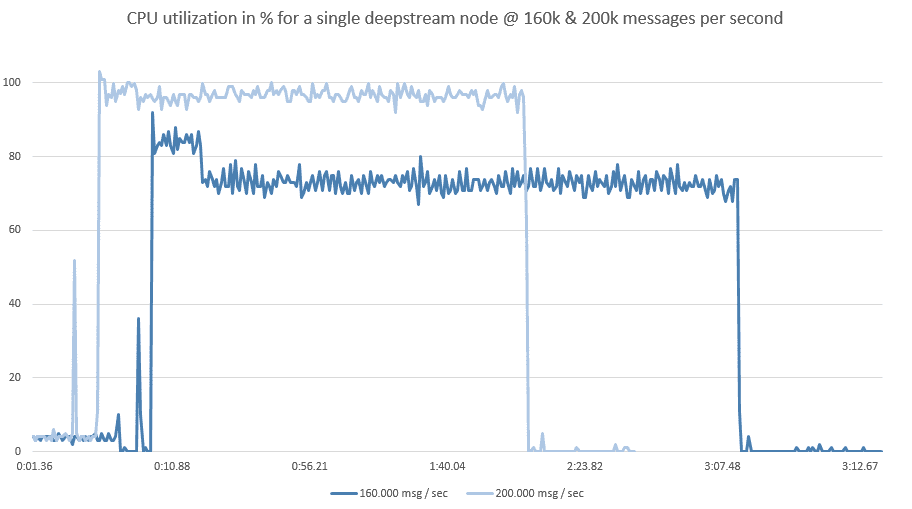
At 10 cents per billion messages this means that we can get almost twice the performance out of a cluster of t2.medium instances than we would from c4.2xlarge.
But what about memory? Fortunately that isn’t too much of a concern. deepstream is a stateless, transactional server that - when connected to an external cache - doesn’t hold data itself… memory tends to level around 80MB per node and is freed up for garbage collection almost immediately after messages are processed.
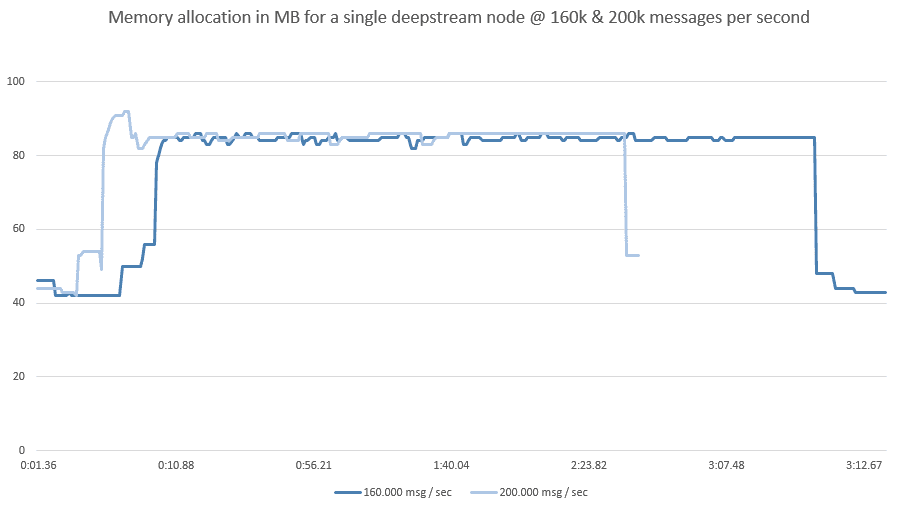
However, there’s one thing to be aware of: deepstream relies on garbage collection to free up dereferenced memory. If a machine’s CPU is overutilized above 100% for a consecutive time, garbage collection will be delayed and memory can add up. If this continues for a prolonged period, the server will run out of memory and eventually crash - so be generous enough when it comes to resource allocation to make sure that your processors get some breathing space every once in a while.
Results - Cluster
Armed with these results, we’ve started looking at subjecting a cluster of six nodes, connected by an AWS Elasticache Redis message bus to a performance test. The goal here was simple - gradually increase the throughput to one million messages per second, then leave the cluster running for a continuous amount of time to monitor CPU and memory usage.
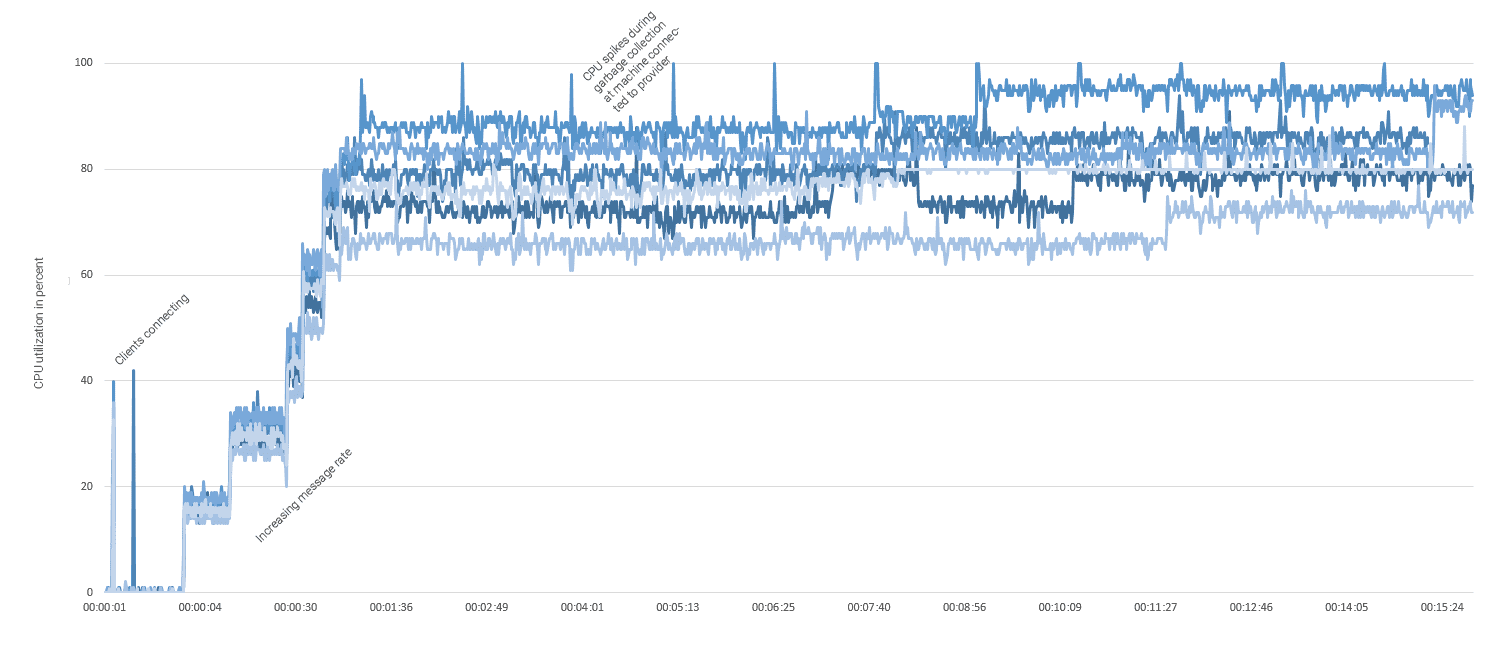
At one million messages per second, average CPU utilisation was at 80%. The node that received the data-input and forwarded it to both the message bus and its connected clients was predictably under higher load with occasional spikes towards the higher 90% range. Memory stayed stable below 80MB with garbage collection leading to volatile spikes during cleanup.
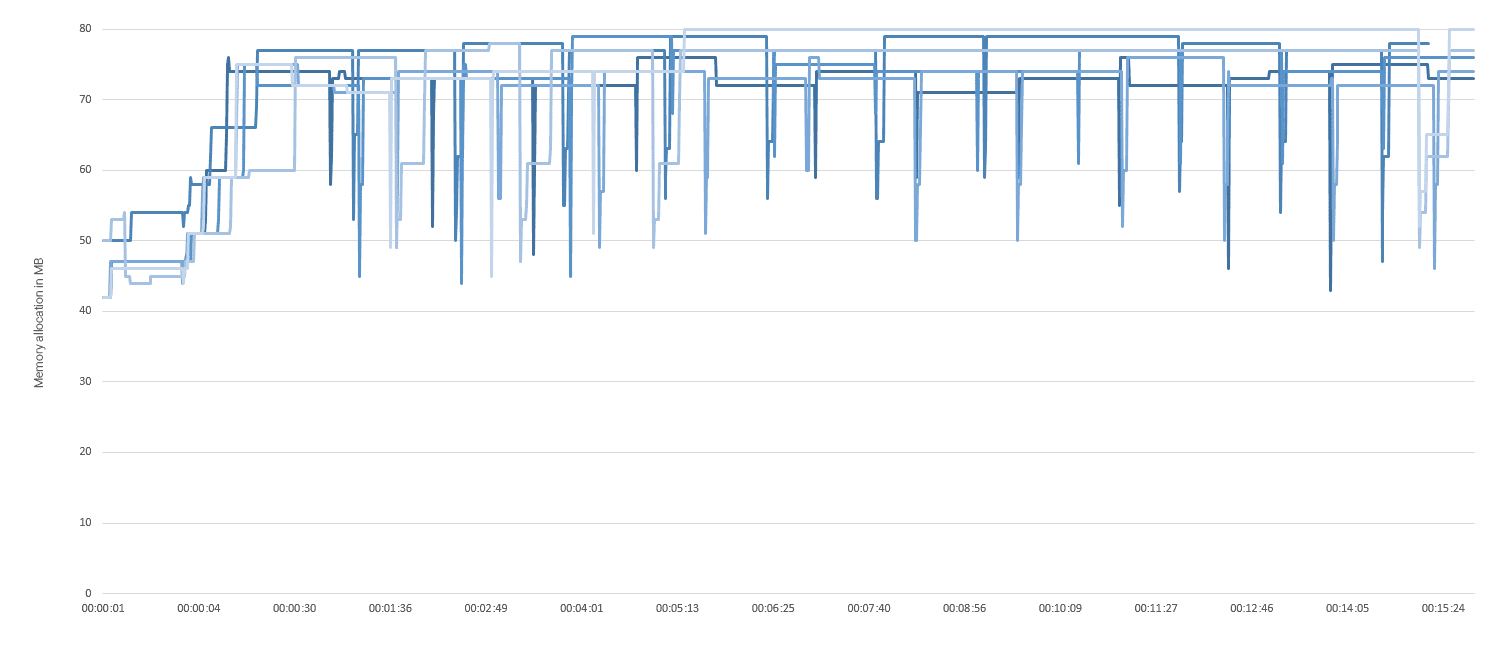
Conclusion
After running variations of this test for up to an hour we can conclude:
- A cluster of six nodes caters reliably for ~four billion messages an hour.
- Clusters scale linearly - larger throughput rates can easily be achieved by adding additional nodes
- The costs of running a six-instance cluster for an hour on AWS are 36 cents (6 x t2.medium @ 0.052$/h + 1 x cache.t2.medium @ 0.068$/h)