Storing Data
Find out how deepstream uses cache and storage systems to store your data
How deepstream stores data
As a standalone server, deepstream keeps all its data in internal memory. In a production cluster however, deepstream servers won’t hold any data themselves. Instead, data is stored in a combination of storage and cache layers that are accessible to all deepstream nodes within the cluster. This allows the individual servers to remain stateless and go down / fail over without causing any data-loss, but it also allows for the data to be distributed across multiple nodes.
deepstream can connect to both a cache and a database at the same time. Whenever a value needs to be stored, it is written to the cache in a blocking fashion and simultaneously written to storage in a non-blocking way.
Similarly, whenever an entry needs to be retrieved, deepstream looks for it in the cache first and in storage second. If the value can only be found in storage, deepstream will load it into the cache for faster access.
So why have this distinction between cache and storage at all?
Because they complement each other quite well!
- Caches need to make relatively small amounts of data accessible at high speeds. They usually achieve this by storing data in memory, rather than on disk (although some, e.g. Redis, can write to disk as well). This means that all data is lost when the process exists. Caches also usually don’t offer support for complex queries (although e.g. Hazelcast has some).
- Databases (storage) are slower to read or write to, but offer efficient long-term storage for larger amounts of data and allow for more elaborate ways of querying (e.g. full-text search, SQL joins etc.)
Why doesn’t deepstream store data itself?
deepstream is sometimes compared to projects like Firebase (now part of Google Cloud Platform) - realtime databases that let users create streaming queries.
While deepstream is a great fit for similar use-cases, it’s conceptually quite different: deepstream’s design-philosophy is inspired by the way multiplayer-game servers or financial streaming works, rather than by datastores.
It can be used as a blazingly fast standalone server without any data-layer, but can also cater for large-scale collaboration apps with demanding storage requirements when connected to both a cache and a database.
Finally, we’ve taken the lessons learned from fixed stack frameworks like Meteor to heart. deepstream is a fast and versatile realtime server - but it doesn’t try to be anything more than that.
We believe that web technology is moving away from the monolithic enterprise stacks of the past towards a vibrant ecosystem of highly specialized microservices - and our goal is to make deepstream thrive within this ecosystem by making it usable with as many programming languages, frontend frameworks, databases, caches, loggers, identity management systems or deployment environments possible.
Connecting to a cache or database
deepstream uses different types of “connectors” - plugins that enable it to interface with other systems.
Cache connectors are plugins that connect deepstream to an in-memory cache, e.g. Redis, Memcached, IronCache, Hazelcast or Aerospike.
Storage connectors are plugins that connect deepstream to a database, e.g. MongoDB, CouchDB, Cassandra or Amazon’s DynamoDB.
Choosing a database and cache
When it comes to choosing a database and cache, there are a few things to take into account:
- Choose systems that scale in the cloud deepstream can scale horizontally across many computers or instances in the cloud. But that won’t help much if your database or cache doesn’t do the same. Fortunately, most popular solutions offer some form of sharding, clustering or cloud-replication, but not all cloud services support that. If you’re using AWS for instance and consider ElastiCache with Redis as a caching engine, your deployment is limited to a single machine.
- Choose systems that complement each other Some caches like Redis store data to disk and can be used without a database. Some systems like Hazelcast or Redis offer both caching and pub/sub messaging, eliminating the need for a separate message-bus. Some in-memory only caches like Memcached are extremely fast, but need to be backed by a database for persistent storage. Some databases offer very fast read performance and a build-in caching layer, so could be used by themselves (make sure to register them as a cache though since otherwise deepstream might fall back to its internal cache and use the potentially stale data within).
- Object/Document/NoSQL databases make more sense than relational ones deepstream’s data-structures are small, independent chunks of JSON, identified by a unique key that can be organized in collections. This makes them a natural fit for object or document oriented databases like Mongo, Rethink or Couch. deepstream also works with relational databases like MySQL, PostGre or Oracle, but doesn’t take advantage of their data-modelling capabilities.
- Be careful when using external x-as-a-service providers It can be tempting to use a fully managed cache from an infrastructure-as-a-service provider, but be aware if its hosted outside of your datacenter: deepstream constantly interacts with its cache and every millisecond in network latency will slow down your application. Equally, a lot of cache / database protocols are designed for use within a trusted environment and therefor unencrypted. If your database lives outside of your network, make sure to use TLS or choose a service that offers a VPN.
Downloading and installing connectors
deepstream connectors are available for many popular databases and caches and we’re constantly looking to expand the selection. You can find an overview of available connectors on the tutorials page. Connectors can be installed via deepstream’s commandline interface, using the cache or storage keyword, e.g.
deepstream install cache redis
deepstream install cache memcached
deepstream install storage mongodb
deepstream install storage rethinkdb
# or on windows using deepstream.exe
deepstream.exe install storage rethinkdbEach connector requires specific configuration parameters. These can be configured in deepstream’s config.yml file (found either in your deepstream’s conf directory or on linux in /etc/deepstream/). When installing a connector, it usually prints an example of the most common settings.
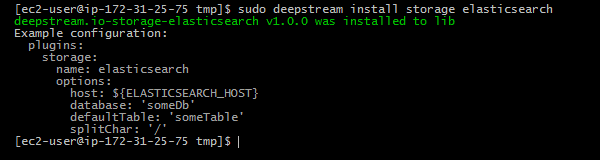
Cache connectors are configured in the config’s plugins - cache section, database connectors in plugins - storage
If you’re using deepstream from Node, it’s also possible to download connectors from NPM. All connectors follow the naming convention deepstream.io-type-name, e.g. deepstream.io-storage-rethinkdb.
Writing your own connector
If you can’t find a connector for your system of choice, you can also write your own quite easily in C++ with Node bindings or in Node.js. If you’re happy with the way your connector turned out, please consider contributing it. To do so, have a look at deepstream’s contribution guidelines
For a guide into how to implement your own connection, please refer to the custom plugin guides.